


شرکتها میتوانند دادهها را از طریق پلتفرمهای مختلف، مانند ایمیل، چت، سرورهای مبتنی بر ابر، تماسهای تلفنی، جلسات ویدیویی و حتی ایمیل فیزیکی به اشتراک بگذارند. آنها همچنین می توانند تمام منابع داده خود را در یک پایگاه داده ادغام کرده و به صورت مجازی به آن دسترسی داشته باشند، به این معنی که برای دسترسی به آن، نیازی به انتقال فیزیکی داده ها از یک پایگاه داده به پایگاه داده دیگر نیست. یادگیری بیشتر در مورد فرآیند مجازی سازی داده ها ممکن است به شما کمک کند تا بفهمید چگونه می توانید با استفاده از یک میان افزار واحد به حجم زیادی از اطلاعات دسترسی پیدا کنید.
در این مقاله از ایوسی، مجازیسازی دادهها را تعریف میکنیم، نحوه عملکرد این رویکرد را توضیح میدهیم و منابع دادهای را که اغلب از طریق این روش مجازیسازی میشوند فهرست میکنیم.
مطالب مرتبط: مجازی سازی دسکتاپ چیست؟ (به علاوه مزایا و انواع)
مجازی سازی داده ها چیست؟
مجازی سازی داده ها که به عنوان حالت مجازی نیز شناخته می شود، به فرآیندی اشاره دارد که کاربران را قادر می سازد از یک رابط واحد برای دسترسی و مدیریت داده ها از منابع مختلف استفاده کنند. این دادهها میتوانند دیجیتال یا فیزیکی باشند و در مکانهای مختلف مانند پایگاههای اطلاعاتی مختلف در اینترنت یا حتی در شهرها، استانها یا کشورهای مختلف باشند. به عنوان مثال، یک شرکت می تواند نقاشی های نمایش داده شده در موزه ای در ونکوور و سایر نقاشی های نمایش داده شده در یک گالری در مونترال را مجازی کند. با استفاده از رایانه یا هدست واقعیت مجازی، ممکن است مانند زمانی که در آن شهرها بودید، نقاشی ها را ببینید و از آن لذت ببرید.
مجازیسازی دادهها همچنین به شما امکان میدهد دادههای موجود را ادغام و دستکاری کنید، به این معنی که میتوانید آنها را برای بهبود آن تغییر دهید یا نشان دهید که دادههای اصلی چگونه بودهاند. به عنوان مثال، فرض کنید که یک سازمان برخی از قطعات هنر بومی باستانی را از طریق کاوشهای باستانشناسی در آلبرتا بازیابی میکند و از هوش مصنوعی (AI) برای بازسازی مجازی آنها استفاده میکند. سپس سازمان می تواند قطعات اصلاح شده را مجازی سازی کند و به عموم مردم نشان دهد که در ابتدا چگونه بوده اند.
بیشتر بخوانید: مجازی سازی چیست و چگونه کار می کند؟ (با انواع)
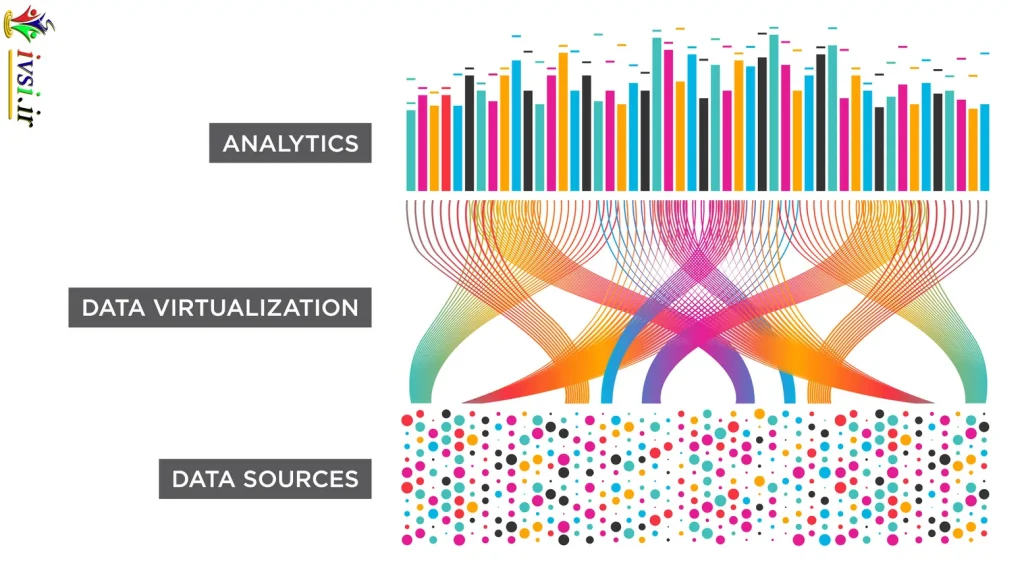
مجازی سازی داده ها چگونه کار می کند؟
این فرآیند از طریق استفاده از میان افزار کار می کند، که یک برنامه کامپیوتری است که برای دسترسی به داده های یکپارچه در زمان واقعی از منابع متعدد طراحی شده است. این نرم افزار کاربران را قادر می سازد تا پایگاه های داده های مختلف را بدون توجه به تفاوت های آنها، ترکیب پلتفرم ها و دستگاه ها و نمایش نتایج در یک رابط، بررسی کنند. میان افزار می تواند این کار را انجام دهد زیرا از طریق سطوح یا لایه های سازماندهی شده برای تعامل بین آنها کار می کند. هر سطح دارای عملکردهای خاصی است که به مجازی سازی داده ها کمک می کند. در اینجا نحوه کار آن آمده است:
لایه اتصال
این لایه شامل یک سری اتصال دهنده است که به کاربران نهایی امکان دسترسی به مدل های داده های شماتیک را می دهد. در این سطح، کاربر درخواست دسترسی میکند و سیستم آن را به آنها اعطا میکند و به آنها امکان میدهد چندین منبع داده را ببینند، اما تفسیر نکنند. این منابع شامل پلتفرمهای رسانههای اجتماعی، وبسایتها، پایگاههای داده SQL، انبارهای داده، فایلهای مسطح مانند TXT یا XML، سیستمهای کلان داده، برنامههای MBaaS و SaaS، صفحات گسترده و سرویسهای پخش میشوند.
به عنوان مثال، حسابداری که می خواهد توسعه مالی یک صنعت را برای ده سال آینده پیش بینی کند، ممکن است از یک سیستم حالت مجازی برای دسترسی همزمان به صفحات گسترده متعدد مرتبط با وضعیت مالی صنعت استفاده کند. این سیستم می تواند تمام منابع مالی را که به آنها دسترسی دارند نشان دهد، اما نه خود داده ها را. در این سطح، آنها فقط می توانند ارزیابی کنند که منبع برای هدف آنها مناسب باشد.
مطالب مرتبط: iPaaS چیست؟ راهنمای یکپارچه سازی پلت فرم به عنوان یک سرویس
لایه انتزاعی
لایه انتزاعی یک نمای منطقی از داده ها ارائه می دهد، به این معنی که به شما اجازه نمی دهد نمایش نهایی اطلاعاتی را که به آن دسترسی دارید مشاهده کنید. این لایه داده ها را بازیابی و ذخیره نمی کند، اما به سیستم حالت مجازی اجازه می دهد تا نظم منطقی به داده ها اختصاص دهد و ساختار اصلی خود را حفظ کند. در این سطح، کاربر نهایی می تواند اسناد را وارد کند و سیستم ویژگی های ابرداده آنها را به طور خودکار حفظ می کند.
این ابرداده ممکن است شامل جداول، فرمول ها، برچسب ها، ردیف ها، ستون ها، اعداد و نام ها باشد. در اینجا، سیستم حالت مجازی همچنین می تواند داده های تجاری را نقشه برداری، تأیید، محافظت و طبقه بندی کند. به عنوان مثال، با الگوبرداری از حسابدار، در این سطح، متخصص می تواند صفحات گسترده و اسناد TXT را وارد کند و سیستم می تواند آنها را بدون تغییر ساختار اصلی آنها در یک نظم منطقی نگه دارد.
مطالب مرتبط: مهندس ابر چه می کند؟ (و چگونه یکی شویم)
لایه مصرفی
در لایه مصرف کننده، کاربران نهایی می توانند به مجموعه ای از ابزارها دسترسی داشته باشند که به آنها اجازه می دهد داده ها را به شکل اصلی آن تفسیر و تجسم کنند. آنها این کار را از یک نقطه منحصر به فرد انجام می دهند، زیرا هدف سیستم حالت مجازی این است که آنها احساس کنند که به یک پایگاه داده منحصر به فرد دسترسی دارند که شامل تمام اطلاعات مورد نظر آنها است. در این سطح، سیستم از یک سری برنامه های کامپیوتری واسطه مانند یک رابط برنامه نویسی کاربردی (API) برای پردازش تمام داده های انتزاعی از لایه قبلی استفاده می کند.
سیستمهای حالت مجازی میتوانند این کار را برای چندین کاربر به طور همزمان انجام دهند و به آنها اجازه دسترسی همزمان به دادههای مجازیسازی شده مشابه را میدهند. به عنوان مثال، به دنبال مثال حسابدار، در این سطح، متخصص می تواند صفحات گسترده و اسناد را باز کند و محتوای آنها را تجزیه و تحلیل کند، و آنها را قادر می سازد آینده مالی صنعت را پیش بینی کنند.
مطالب مرتبط: مروری بر SDK در مقابل API (با اهمیت و مثال)
منابع داده رایج از طریق سیستم های حالت مجازی مجازی سازی شده اند
در اینجا برخی از منابع داده وجود دارد که شرکت ها می توانند از طریق سیستم های حالت مجازی مجازی سازی کنند:
صفحات گسترده و فایل های مسطح
صفحات گسترده اسنادی هستند که حاوی مجموعه ای از داده ها هستند، معمولاً داده های مالی، که در ستون ها، ردیف ها و سلول ها سازماندهی شده اند. این اسناد می توانند شامل متن، اعداد، فرمول ها، شرایط، برنامه ها و ماکروها باشند. صفحات گسترده برای ایجاد و درک آسان هستند، که آنها را برای بسیاری از صنایع مانند بانکداری، تولید یا ساخت و ساز ارزشمند و مفید می کند.
فایل های Flat اسناد باینری هستند که برای باز کردن آنها نیازی به نرم افزار خاصی نیست. این اسناد معمولاً فایل های متنی هستند که می توانند حاوی هر نوع داده ای مانند اعداد، فرمول ها، کدها و متن باشند. نگهداری آنها بسیار آسان است زیرا به فضای ذخیره سازی حداقلی نیاز دارند. سیستمهای حالت مجازی میتوانند به راحتی این فایلها را مجازیسازی کنند، زیرا انعطافپذیر هستند و مدیریت آنها آسان است.
مطالب مرتبط: نحوه حذف رمز عبور در اکسل (با نکاتی برای محافظت)
اطلاعات بزرگ
کلان داده شامل مقادیر زیادی از اطلاعات تولید شده توسط چندین منبع تجاری است که توسط سیستم های مختلف در رابطه با صحت، حجم، تنوع و سرعت آنها اندازه گیری می شود. کلان داده می تواند به اطلاعات ساختاریافته و بدون ساختاری اشاره داشته باشد که شرکت ها می توانند در دریاچه های داده یا انبارهای داده ذخیره کنند. به دلیل اندازه آن، دانشمندان کامپیوتر و آماردانان نمی توانند داده های بزرگ را با استفاده از اعداد اندازه گیری کنند، که تجزیه و تحلیل آن را دشوار می کند.
برای اینکه بتوانند این کار را انجام دهند، به ابزارهای هوش مصنوعی (AI) و یادگیری ماشین (ML) نیاز دارند تا داده های بزرگ را به مجموعه داده ها تقسیم کنند و اطلاعات را سریعتر جمع آوری، طبقه بندی و تجزیه و تحلیل کنند. مجازیسازی کلان دادهها ممکن است به زمان، ترکیبی از سیستمهای هوش مصنوعی و ML و روشهای تعریفشده برای نحوه تجسم کاربر نهایی این اطلاعات نیاز داشته باشد.
مطالب مرتبط: چگونه به یک تحلیلگر کلان داده تبدیل شویم (با انتظارات حقوق)
انبارهای داده
انبار داده، مخزن داده ای است که شرکت ها می توانند از آن برای ذخیره اطلاعات تاریخی استفاده کنند. سپس، کسبوکارها میتوانند برای تحلیل و پیشبینی روندهای بازار، ارزیابی ایدههای محصول جدید، یا درک استراتژیهای تجاری در موقعیتهای قبلی به دادهها دسترسی داشته باشند. اساساً، هدف انبار داده این است که یک شرکت را قادر می سازد تا تجزیه و تحلیل هوش تجاری (BI) را انجام دهد، فایل ها و اطلاعات ضروری خود را مدیریت کند، از تصمیمات تجاری پشتیبانی کند و به شرکت در یافتن راه حل های عملی کمک کند.
این انبارها میتوانند حاوی فایلهای مسطح، صفحات گسترده یا فایلهای PDF باشند که یک شرکت میتواند برای محافظت از دادههای خود ذخیره کند. با مجازیسازی یک انبار داده، یک شرکت میتواند بخشی از دادههای تاریخی خود را افشا کند و در زمان واقعی آن را برای عموم در دسترس قرار دهد.
مطالب مرتبط: Data Mart در مقابل Data Warehouse (با مزایا و نکات)
دریاچه های داده
دریاچههای داده مخازن دادههایی هستند که حاوی دادههای ساختاریافته و بدون ساختار یا خام هستند تا به توسعهدهندگان، دانشمندان رایانه و دانشمندان داده کمک کنند تا همه دادههای تجاری را که برای انجام فعالیتهای خود استفاده میکنند، ذخیره کنند. دادههای ذخیرهشده در دریاچه دادهها هیچ محدودیت ذخیرهسازی از پیش تعریفشدهای ندارند، به این معنی که دریاچههای داده میتوانند بسیار بزرگ شوند. این متخصصان می توانند از دریاچه داده برای پردازش کلان داده ها، آموزش سیستم های یادگیری ماشینی برای انجام تجزیه و تحلیل و حمایت از تحلیلگران تجاری در تصمیم گیری استفاده کنند.
مجازی سازی یک دریاچه داده ممکن است به زمان و یک سری کاربردهای پیچیده نیاز داشته باشد که ممکن است به اندازه مخزن بستگی داشته باشد. با انجام این کار، شرکتها میتوانند به سایر دانشمندان داده که با آنها مرتبط نیستند، اجازه دسترسی به دادههای آنها را بدهند و به آنها در اعمال تغییرات تجاری کمک کنند.
مطالب مرتبط: دریاچه داده در مقابل انبار داده (به علاوه مهارت های مدیریت داده)
داده های ابری
این به داده های ذخیره شده در ابر توسط چندین شرکت که از یک بستر و فضای ذخیره سازی ابری یکسان استفاده می کنند، اشاره دارد. این بدان معناست که آنها اطلاعاتی را که در فضای ابری ذخیره میکنند با یکدیگر به اشتراک میگذارند و متخصصان شرکتهای مختلف را قادر میسازند تا دادههای موجود در ابر را با هم تجزیه و تحلیل کنند. با انجام این کار، کسب و کارها می توانند تجزیه و تحلیل کسب و کار را بهبود بخشند، تصمیمات بهتری بگیرند و آنچه ارائه دهندگان، رقبا یا رهبران بازار انجام می دهند را مطالعه کنند. آنها همچنین می توانند از داده های ابری برای به اشتراک گذاری اطلاعات پیچیده با هدف کمک به شرکت های مختلف برای همکاری با یکدیگر در یک پروژه استفاده کنند.
به عنوان مثال، تمام شرکت هایی که در ساخت قطعات مختلف یک مدل خودرو مشارکت دارند، ممکن است از داده های ابری برای به اشتراک گذاری اطلاعات خود استفاده کنند. آنها این کار را انجام می دهند زیرا کاری که یک تیم انجام می دهد ممکن است بر آنچه تیم های دیگر طراحی یا ایجاد می کنند تأثیر بگذارد. مجازی سازی این اطلاعات نسبتاً آسان است، زیرا تمام داده های موجود در اینجا به داده های ساخت یافته اشاره دارد.